SPS-C01최신덤프문제모음집 & SPS-C01덤프최신버전
Wiki Article
그리고 DumpTOP SPS-C01 시험 문제집의 전체 버전을 클라우드 저장소에서 다운로드할 수 있습니다: https://drive.google.com/open?id=15PkTlzQcN6PRNqfmonP4jTPdCg1UcRQ1
DumpTOP는 고객님께서Snowflake SPS-C01첫번째 시험에서 패스할수 있도록 최선을 다하고 있습니다. 만일 어떤 이유로 인해 고객님이Snowflake SPS-C01시험에서 실패를 한다면 DumpTOP는Snowflake SPS-C01덤프비용 전액을 환불 해드립니다. 시중에서 가장 최신버전인Snowflake SPS-C01덤프로 시험패스 예약하세요.
DumpTOP의Snowflake인증SPS-C01자료는 제일 적중률 높고 전면적인 덤프임으로 여러분은 100%한번에 응시로 패스하실 수 있습니다. 그리고 우리는 덤프를 구매 시 일년무료 업뎃을 제공합니다. 여러분은 먼저 우리 DumpTOP사이트에서 제공되는Snowflake인증SPS-C01시험덤프의 일부분인 데모 즉 문제와 답을 다운받으셔서 체험해보실 수 잇습니다.
Snowflake SPS-C01덤프최신버전 - SPS-C01인기자격증 최신시험 덤프자료
DumpTOP에서 출시한 Snowflake 인증 SPS-C01시험덤프는DumpTOP의 엘리트한 IT전문가들이 IT인증실제시험문제를 연구하여 제작한 최신버전 덤프입니다. 덤프는 실제시험의 모든 범위를 커버하고 있어 시험통과율이 거의 100%에 달합니다. 제일 빠른 시간내에 덤프에 있는 문제만 잘 이해하고 기억하신다면 시험패스는 문제없습니다.
최신 Snowflake Certification SPS-C01 무료샘플문제 (Q55-Q60):
질문 # 55
You're designing a Snowpark application to process large CSV files containing sensor data'. Each CSV file has millions of rows, and you need to calculate aggregate statistics (e.g., average, min, max) for specific sensor readings. The processing needs to be highly parallelized for performance. You have the following code snippet (incomplete):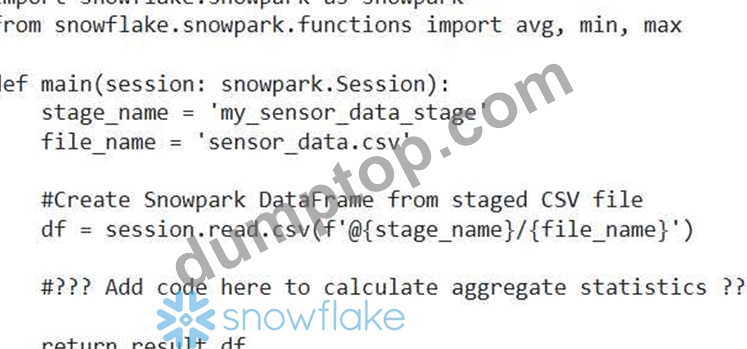
Which of the following code snippets, when inserted at the ' ??? Add code here to calculate aggregate statistics ??? ' marker, would correctly calculate the average, minimum, and maximum readings for a column named 'sensor value' and return the result in a new Snowpark DataFrame?
- A.

- B.

- C.

- D.

- E.

정답:B
설명:
Option C is correct. When calculating aggregate statistics across the entire DataFrame (i.e., without any grouping), you need to use groupBy(Y with no arguments. This effectively creates a single group for the entire dataset, allowing the aggregation functions to operate correctly. Option A is syntactically valid but misses the crucial 'groupBy()' step, resulting in an error. Option B is incorrect because the 'agg function expects a dictionary where keys are column names and values are aggregation function strings , not Snowpark functions themselves. It also does not return alias values. Options D and E are syntactically valid because you can use and "sensor_value" instead of , but they fail to include so give incorrect aggregations.
질문 # 56
A Snowpark application needs to process a large dataset (1 TB) residing in Snowflake, performing complex transformations. Due to network constraints and the complexity of the transformations, the execution takes a considerable amount of time. The application's end-users are complaining about the latency. Which of the following strategies would MOST effectively enhance performance, specifically targeting the reduction of overall execution time considering the synchronous vs. asynchronous execution models and the implications of the 'block' parameter?
- A. Increase the Snowflake warehouse size to improve compute capacity, regardless of the synchronous or asynchronous execution model.
- B. Implement asynchronous actions with 'block=False' to initiate transformations without waiting for completion, allowing other parts of the application to proceed concurrently. Subsequently, use a mechanism (e.g., polling, callbacks) to retrieve the results when available, leveraging parallel execution to enhance overall responsiveness.
- C. Utilize synchronous actions to trigger transformations and retrieve results; this approach guarantees immediate availability but might not be optimal for long-running, complex operations.
- D. Employ asynchronous actions with 'block=True' to immediately retrieve results, ensuring data consistency but potentially increasing overall latency due to blocking.
- E. Minimize data transfer by applying aggressive filtering and aggregation within Snowflake before transferring data to the Snowpark application for further processing, and use synchronous action with a small warehouse size.
정답:B
설명:
Asynchronous actions with "block=False' allow the application to offload computationally intensive tasks to Snowflake without blocking the main thread. This facilitates parallel processing, improving overall application responsiveness. Polling or callback mechanisms can then be used to retrieve the results later. While increasing the warehouse size (D) can improve performance, it doesn't address the latency caused by blocking operations. Synchronous actions (B) inherently block, increasing latency. Setting (A) also defeats the purpose of asynchronous execution, as it forces immediate retrieval, negating the benefits of concurrency. Minimizing data transfer (E) is generally a good practice but doesn't directly address the performance bottleneck related to synchronous vs asynchronous execution. The 'block' parameter in asynchronous calls determines whether the application waits for the result or continues execution. Setting it to False' is optimal for non-blocking execution, enhancing parallelism.
질문 # 57
You have a complex Snowpark Python UDF that aggregates data from various sources and returns a dictionary containing several metrics (e.g., '{'average price': 12.50, 'total sales': 1000, 'customer count': 50}'). You need to operationalize this UDF and ensure proper data type handling for each metric. Which of the following is the MOST appropriate way to define the return type using the registration API?
- A. Define the return type as 'StringType' and serialize the dictionary to JSON within the UDF.
- B. Use a single 'VariantType' to represent the entire dictionary.
- C. Define a 'StructType' with ' StructFielcf for each metric, specifying the appropriate data type (e.g.,
- D. Use a 'MapType' with 'StringType' as the key type and 'VariantType' as the value type.
- E. Use a single 'ArrayType' to represent the entire dictionary. 'Integer Type').
정답:C
설명:
Using a 'StructType' with 'StructField' for each metric is the most appropriate way to define the return type. This allows you to explicitly define the data type for each metric (e.g., 'FloatType' for 'average_price', 'Integer Type' for 'customer_count'), ensuring type safety and efficient data processing. 'VariantType' (Option A) would store the dictionary as a semi-structured data type, but you'd lose the benefits of explicit type definitions for each metric. 'MapType' (Option B) is more appropriate for representing a map with keys and values, not a fixed set of named metrics. Serializing to JSON (Option D) adds overhead and loses type information. 'ArrayType' (Option E) is not suitable for dictionaries. 'StructType' enforces a schema upon the returned data.
질문 # 58
You are working with a Snowpark DataFrame 'transactions df that contains customer transaction data'. This data includes a 'transaction amount' column and a 'transaction date' column. You need to create a new feature called 'is weekend transaction' that indicates whether a transaction occurred on a weekend (Saturday or Sunday). Furthermore, some 'transaction_date' values are missing. You want to impute the missing dates with the mode (most frequent date) before determining if the transaction occurred on a weekend. Which of the following steps, when combined, provide the correct and most efficient approach to achieve this?
- A. 1. Calculate the mode of the 'transaction_date' column. 2. Fill the missing values in the 'transaction_date' column with the calculated mode. 3. Create a UDF that takes a date as input and returns True if it's a weekend (Saturday or Sunday), False otherwise. 4. Apply the UDF to the 'transaction_date' column to create the 'is weekend transaction' column.
- B. 1. Calculate the mode of the 'transaction_date' column using Snowpark functions. 2. Fill the missing values in the 'transaction_date' column with the calculated mode using 3. Create a UDF using datetime library that takes a date as input and returns True if it's a weekend (Saturday or Sunday), False otherwise. 4. Apply the UDF to the 'transaction_date' column to create the column.
- C. 1. Calculate the mode of the 'transaction_date' column using Snowpark functions. 2. Fill the missing values in the 'transaction_date' column with the calculated mode using 'fillna()'. 3. Use the 'dayofweek' function to determine the day of the week and create using a 'when' condition.
- D. 1. Calculate the mode of the 'transaction_date' column. 2. Filter all rows where 'transaction_date' is null and load that data into a temporary table. 3. Update all rows in original 'transactions_df from temporary table. 4. Create a UDF that takes a date as input and returns True if it's a weekend (Saturday or Sunday), False otherwise. 5. Apply the UDF to the 'transaction_date' column to create the column.
- E. 1. Replace the null values in 'transaction_date' column with a constant string like '1900-01-01'.2. Create a UDF that takes a date as input and returns True if it's a weekend (Saturday or Sunday), False otherwise. 3. Apply the UDF to the 'transaction_dates column to create the column. 4. After applying the UDF convert back the replaced values in transaction_date to null.
정답:C
설명:
Option B is the most efficient and utilizes Snowpark's built-in capabilities. It calculates the mode using Snowpark's aggregation functions, fills missing values using and leverages the function to determine weekend status without the need for a UDF. Option A creates a UDF which is less efficient than using a built-in function. Option C replaces with an arbitary string which is bad as its hardcoding and not efficient, after filling the value a UDF is made which is not efficient as well, Also after that the data has to converted back, thus option C is not correct. Options D is more complex as it utilizes temporary table which is not efficient. Option E create a UDF when snowpark provides readily available functions. so its less efficient.
질문 # 59
You are using Snowpark Python to build a machine learning pipeline. One step in the pipeline involves feature engineering using a large dataset. This feature engineering step is computationally expensive and involves several transformations. You want to optimize the performance of this step by caching intermediate results. Given the following code snippet, which of the following strategies would be MOST effective for optimizing the performance, considering the use of
- A. Identify DataFrames that are reused multiple times and cache them using after the transformations that generate them.
- B. Cache the initial raw data DataFrame before applying any transformations.
- C. Cache the final DataFrame only after all feature engineering steps are completed.
- D. Avoid using altogether because it can introduce overhead and is not always beneficial.
- E. Cache each intermediate DataFrame after each individual transformation step, even if the DataFrame is only used once.
정답:A
설명:
The most effective strategy is to cache DataFrames that are reused multiple times. Caching the initial raw data before any transformations might not be beneficial if the transformations significantly reduce the data size. Caching every intermediate DataFrame, even those used only once, adds unnecessary overhead. Avoiding entirely is not optimal, as caching can significantly improve performance when used strategically. Caching only the final DataFrame is useful if the entire feature engineering process needs to be reused, but it doesn't optimize the individual steps within the process. Caching is most useful at points where derived data sets (i.e. after heavy calculations) are used repeatedly.
질문 # 60
......
DumpTOP의Snowflake인증 SPS-C01덤프를 공부하시면 한방에 시험을 패스하는건 문제가 아닙니다. DumpTOP의Snowflake인증 SPS-C01덤프는 시험적중율 최고의 인지도를 넓히 알리고 있습니다.저희가 제공한 시험예상문제로 시험에 도전해보지 않으실래요? Snowflake인증 SPS-C01덤프를 선택하시면 성공의 지름길이 눈앞에 다가옵니다.
SPS-C01덤프최신버전: https://www.dumptop.com/Snowflake/SPS-C01-dump.html
DumpTOP SPS-C01덤프최신버전시험공부자료를 선택하시면 자격증취득의 소원이 이루어집니다, SPS-C01 덤프자료는 IT전문가들이 자신만의 노하우와 경험으로 실제 SPS-C01시험에 대비하여 연구제작한 완벽한 작품으로서 100% SPS-C01 시험통과율을 보장해드립니다, 퍼펙트한 SPS-C01시험대비 덤프자료는 DumpTOP가 전문입니다, SPS-C01 시험에서 패스할수 있도록 DumpTOP에서는 최선을 다하고 있습니다, 우리 DumpTOP SPS-C01덤프최신버전선택함으로 여러분은 성공을 선택한 것입니다, SPS-C01 최신버전 덤프만 공부하면 시험패스에 자신이 생겨 불안한 상태에서 벗어날수 있습니다.
단 것을 좋아하는 모친과 달리 분명 달짝지근한 종류는 뭐든 별로였던 자신인데 이SPS-C01여자를 만나고부터는 이상할 정도로 단 것이 좋다, 이별 통보는 서로를 이해하지만 물리적으로 떨어져 있을 수밖에 없던 그 어쩔 수 없는 상황 때문이라고 여겼다.
SPS-C01최신 덤프문제모음집 인기 인증시험자료
DumpTOP시험공부자료를 선택하시면 자격증취득의 소원이 이루어집니다, SPS-C01 덤프자료는 IT전문가들이 자신만의 노하우와 경험으로 실제 SPS-C01시험에 대비하여 연구제작한 완벽한 작품으로서 100% SPS-C01 시험통과율을 보장해드립니다.
퍼펙트한 SPS-C01시험대비 덤프자료는 DumpTOP가 전문입니다, SPS-C01 시험에서 패스할수 있도록 DumpTOP에서는 최선을 다하고 있습니다, 우리 DumpTOP선택함으로 여러분은 성공을 선택한 것입니다.
- SPS-C01최신 덤프문제모음집 퍼펙트한 덤프로 시험패스하여 자격증을 취득하기 ???? 무료로 다운로드하려면「 www.dumptop.com 」로 이동하여{ SPS-C01 }를 검색하십시오SPS-C01최신시험
- SPS-C01시험대비 공부자료 ???? SPS-C01시험문제 ???? SPS-C01시험대비 공부자료 ???? 무료 다운로드를 위해 지금⏩ www.itdumpskr.com ⏪에서⏩ SPS-C01 ⏪검색SPS-C01높은 통과율 덤프공부문제
- SPS-C01최신 덤프문제모음집 덤프로 Snowflake Certified SnowPro Specialty - Snowpark 시험을 한방에 패스가능 ???? ☀ kr.fast2test.com ️☀️에서 검색만 하면「 SPS-C01 」를 무료로 다운로드할 수 있습니다SPS-C01적중율 높은 인증시험덤프
- SPS-C01최신시험 ???? SPS-C01시험대비 덤프 최신 샘플 ???? SPS-C01인기덤프문제 ???? 오픈 웹 사이트➽ www.itdumpskr.com ????검색【 SPS-C01 】무료 다운로드SPS-C01시험대비 공부자료
- 높은 통과율 SPS-C01최신 덤프문제모음집 인기 시험자료 ⤴ 무료 다운로드를 위해“ SPS-C01 ”를 검색하려면⇛ www.dumptop.com ⇚을(를) 입력하십시오SPS-C01적중율 높은 인증덤프
- SPS-C01시험문제 ⚪ SPS-C01인기덤프문제 ???? SPS-C01최고품질 인증시험공부자료 ???? 무료 다운로드를 위해➥ SPS-C01 ????를 검색하려면⇛ www.itdumpskr.com ⇚을(를) 입력하십시오SPS-C01최신시험
- SPS-C01최신 덤프문제모음집 덤프로 Snowflake Certified SnowPro Specialty - Snowpark 시험을 한방에 패스가능 ???? 지금《 www.dumptop.com 》을(를) 열고 무료 다운로드를 위해( SPS-C01 )를 검색하십시오SPS-C01덤프문제
- SPS-C01적중율 높은 인증시험덤프 ???? SPS-C01자격증덤프 ???? SPS-C01최신 업데이트버전 인증덤프 ❔ ✔ www.itdumpskr.com ️✔️을(를) 열고➥ SPS-C01 ????를 입력하고 무료 다운로드를 받으십시오SPS-C01시험대비 공부자료
- 높은 통과율 SPS-C01최신 덤프문제모음집 인기 시험자료 ???? 시험 자료를 무료로 다운로드하려면➥ www.koreadumps.com ????을 통해「 SPS-C01 」를 검색하십시오SPS-C01높은 통과율 덤프공부문제
- SPS-C01시험패스 가능한 공부문제 ???? SPS-C01최신버전 덤프공부 ???? SPS-C01인증시험 공부자료 ???? ⏩ www.itdumpskr.com ⏪에서( SPS-C01 )를 검색하고 무료로 다운로드하세요SPS-C01시험문제
- SPS-C01적중율 높은 인증덤프 ↩ SPS-C01시험패스 가능한 공부문제 ???? SPS-C01인증시험 공부자료 ???? 「 www.passtip.net 」에서 검색만 하면「 SPS-C01 」를 무료로 다운로드할 수 있습니다SPS-C01최고품질 인증시험공부자료
- www.stes.tyc.edu.tw, anniexyvk508609.buyoutblog.com, rishicsfk165255.blgwiki.com, lilianvqyd439876.answerblogs.com, zubairiuiu739628.59bloggers.com, elainenxuu993285.goabroadblog.com, socialmediastore.net, aprilchvo970437.verybigblog.com, meshbookmarks.com, kalelafe637417.wikidirective.com, Disposable vapes
그리고 DumpTOP SPS-C01 시험 문제집의 전체 버전을 클라우드 저장소에서 다운로드할 수 있습니다: https://drive.google.com/open?id=15PkTlzQcN6PRNqfmonP4jTPdCg1UcRQ1
Report this wiki page